Came across this interesting paper that I thought was worth sharing.
If Evolution Strategies really come in handy when reward signals are noisy or non-differentiable, it means that a plethora of real-world use cases will benefit from this approach.
Not to mention its effectiveness in systems that are heavily distributed (e.g., cluster-scale inference).
But exactly what role is the evaluation strategy playing here?
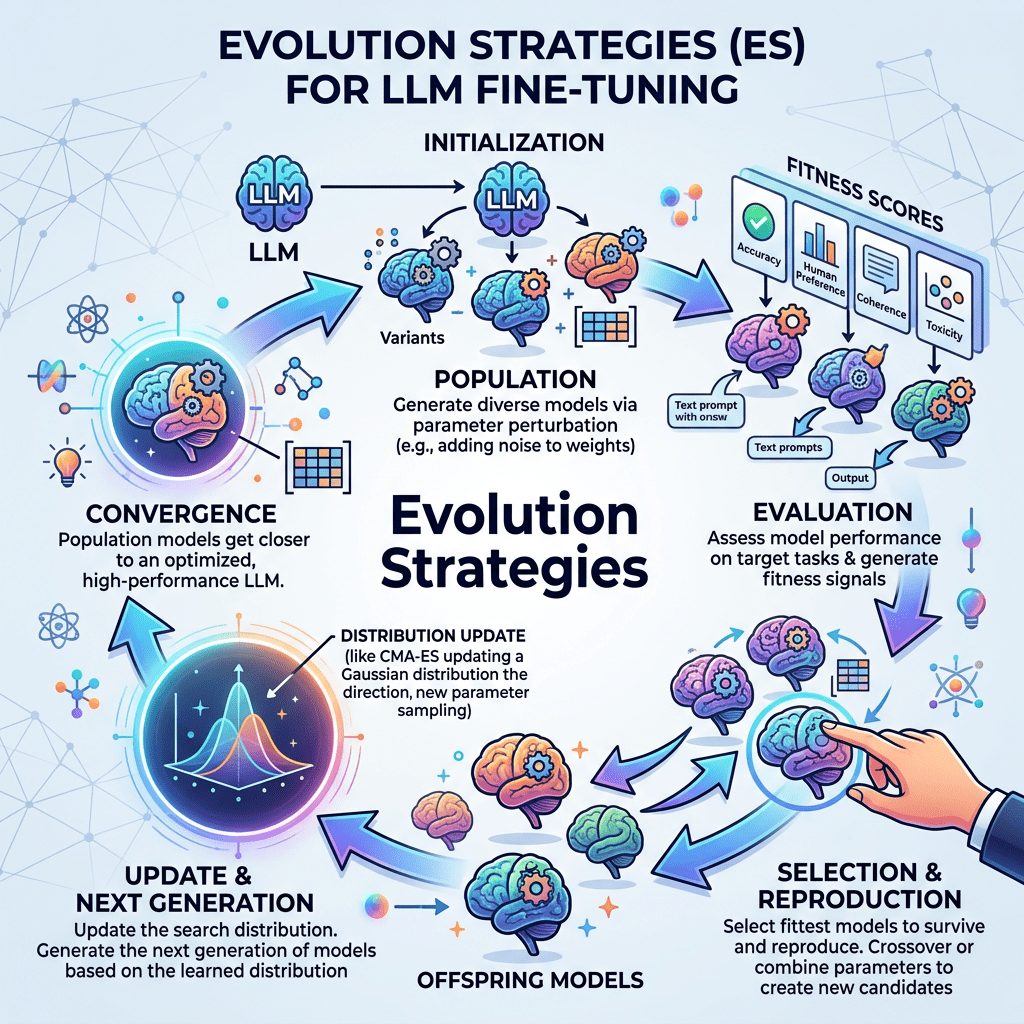
This paper basically proposes replacing or augmenting standard reinforcement learning–based fine-tuning (e.g., RLHF) with Evolution Strategies (ES) for optimizing large language models.
So, instead of gradient-based updates from reward models, ES treats model parameters (or parameter perturbations) as a population and optimizes them via black-box search.
RL-based fine-tuning approaches suffer from a plethora of challenges, such as:
a. Instability and sensitivity to hyperparameters.
b. Credit assignment issues in long sequences.
c. High computational and memory overhead.
Then, Gradient-based methods require differentiable reward signals and backpropagation through long contexts.
So the two key explorative areas here are:
1. Use Evolution Strategies (ES) to optimize LLM behavior:
a. Sample parameter perturbations (noise vectors).
b. Evaluate model outputs using a reward function (e.g., preference model).
c. Update parameters based on the weighted aggregation of perturbations.
2. Parallelization ability across many workers, which obviously leads to strong scaling properties.
Overall, as you can imagine, this opens a path toward gradient-free alignment pipelines for large-scale AI systems.
#AI #ArtificialIntelligence #LLM #RL #ReinforcementLearning #EvolutionStrategies
