
As supply chains embark on their objective to become real-time planning and operations entities, building the technology architecture to support this objective becomes paramount. This is why real-time ecosystems like Kafka can play a critical role in the digital transformation journey to become real-time.
This three-part article will explore how the Kafka ecosystem can help supply chains attain realistic real-time capabilities and generate innovation. In the first part, we will introduce the Kafka ecosystem and its benefits over the traditional client-server architecture. In the subsequent parts of the article, we will explore how Kafka ecosystems can help build real-time capabilities in the supply chain context.
The Kafka ecosystem
Before we jump into the fundamental understanding of the Kafka ecosystem, let us explore the drawbacks of the traditional point-to-point architecture.
Drawbacks of conventional point-to-point architecture
As shown in Figure 1, point-to-point system interactions are challenging to scale.
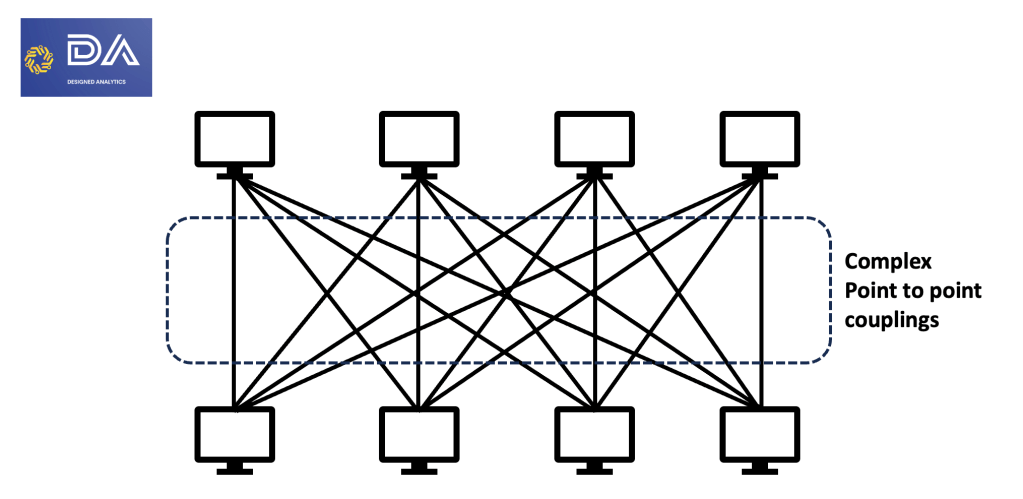
Figure 1: Complexity of point-to-point architecture
Drawbacks of the client-server architecture are:
- Rigid coupling: Since the interaction is based on knowledge of each other, these systems are tightly coupled, making maintenance challenging, precisely when you scale up. This rigid coupling also leaves little room for errors. If one system goes offline, the flow of communication gets hampered.
- Plethora of protocols: Systems in a point-to-point architecture may leverage different protocols and methods ( to scale, handle failures, etc.).This creates a situation where you must maintain various systems for the communication to be executed flawlessly.
- Lack of controls: Receiving systems can not control the traffic they receive. Since they can’t control the pace, they can easily get overwhelmed and operate at the whims of request-making applications.
- Lack of data identification: Point-to-point architecture protocols are so fixated on request and response aspects that there is little to no emphasis on “what.” Essentially, what is being exchanged between systems is minimally relevant in a world where it should be paramount.
- Lack of ability to reconstruct: There is no option to “replay” communications that have already taken place. This lack of ability to reconstruct these communications means a lack of ability to reconstruct the state of a communication system.
Kafka ecosystem to the rescue
As you can imagine, just by looking at Figure 1, the architecture needs to introduce a communication hub designed to address the drawbacks highlighted above. This hub should allow the systems to communicate without knowledge of each other. And that is precisely what a Kafka cluster is. Kafka removes the complexity of point-to-point communication by acting as a communication hub.
Figure 2 shows the Kafka communication model. Before you start reading subsequent sections, take a minute to ponder upon this diagram and compare it against Figure 1.
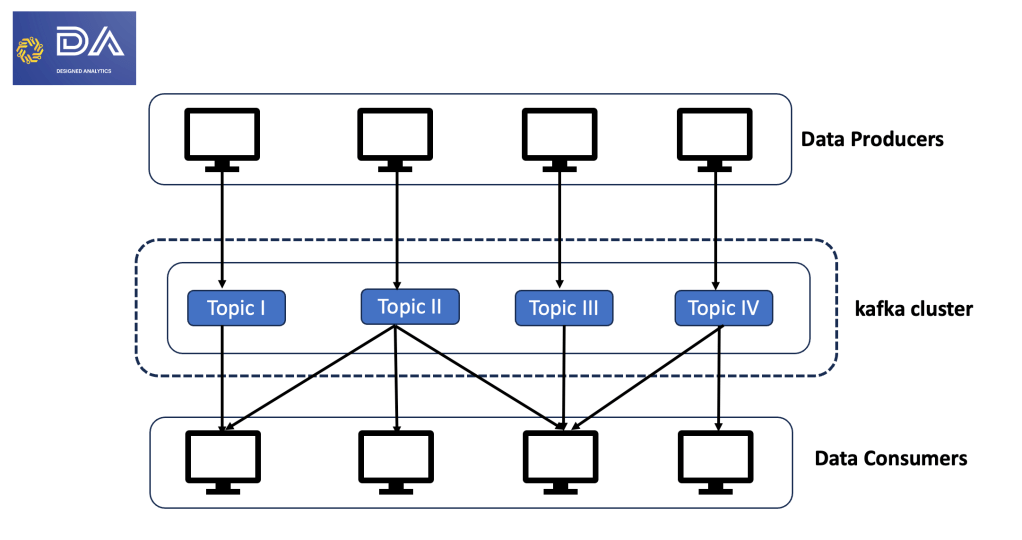
Figure 2: The Kafka communication model
Some aspects you may observed are:
- Producing systems publish their data and do not have to worry about who reads that data. That is what the topics are in Figure 2.
- Each topic is a data stream stored on the Kafka cluster. While serving the same purpose as tables in a database, these topics do not impose any specific schema. They store raw data, and this aspect introduces a lot of flexibility.
- The consumer systems are the systems and processes that consume or read the topics. A consumer may read one or more topics. As evident from Figure 2, these consumers do not communicate with producer systems at all. They just tap into relevant topics.
- Consumer systems and processes can sync together to form groups. Known as consumer groups, it helps distribute work across multiple processes.
Advantages
To summarize, the Kafka approach offers the following advantages:
- Decoupling of systems makes maintenance much easier
- Delivery reliability due to asynchronous communication. Consumers can pick up where it left off in case it goes offline.
- Standardization capability, both on the communication protocol and scaling & fault tolerance.
- Consumer systems determine the rate of data consumption. So, if the data volume in the stream explodes, the Kafka layer can act as a buffer.
- A much better understanding of the data being communicated. The concept of “events” defines the data and the corresponding structure.
- The architecture can restore its state by replaying events under corresponding topics.
Now that we know the advantages that Kafka ecosystems provide, in the second part of this article, we will start exploring why it is imperative to leverage such an architecture in the real-time supply chain capabilities we envision.
The second part of the article can be found here.
References:
- Querying Kafka with Kafka Streams, Oreilly
- Getting Started with Kafka Streams, Oreilly
- Kafka Streams: Deploy a Local Kafka Cluster, Oreilly Lab
- Unlocking the Value of Real-Time Analytics, Oreilly
