
While in the first part of the article, we overviewed what the field of Deep Reinforcement learning is about, we started exploring some fundamental terminology in the second part and third parts. In the fourth part, we explored the temporal credit assignment problem. In the fifth part, we will explore the exploration vs exploitation trade-off.
As we highlighted in the fourth part, there is a score associated with reward, indicating the strength of the reward. A weak reward, in many cases may not provide any supervision to the agent. Essentially, the reward may indicate goodness and not correctness. What this means is that this reward may contain information on other potential rewards. Because of this, evaluative feedback learning becomes important. And this need for evaluative feedback means there is a need for exploration.
We know that exploration is the process that enables the agent to improve its knowledge about each action, and this knowledge can lead to long term benefit. However, the agent must be able to balance the gathering of information with the exploitation of the information that it currently has. This is what is known as exploration vs exploitation made-off in the reinforcement learning parlance.
Just like the last part, let us first explore this with the help of a non-technical example. Rob is a greedy guy who is always jealous 😁 Robert sees someone digging for gold and they start digging too. However, the other guy is a geologist and knows the exact spot where the gold is. As Robert digs with no success but a lot of sweat, he sees that the other guy reaches the gold pile and walks away with it. Rob is not only jealous but also greedy. As soon as this other guy walks way with the gold, Rob starts digging at the same spot.
If there is gold beneath the ground, it may very well have been where Rob was initially digging. But Rob got greeedy and decided to change the spot, based on his observation. Essentially, Rob adopted a greedy action, a result of his greedy policy. Little does Rob know that his greedy policy will fail. All the gold that was at this spot has already been dug.
When the geologist found the gold, the only piece of information that Rob obtained was the depth at which the gold was found. Unlike the geologist, Rob has no idea about what lies beyond that depth. The fact is that the gold may be in close proximity of where Rob was digging in the beginning or it may be at a completely different place.
The same dilemma exists in the reinforcement learning world as well.
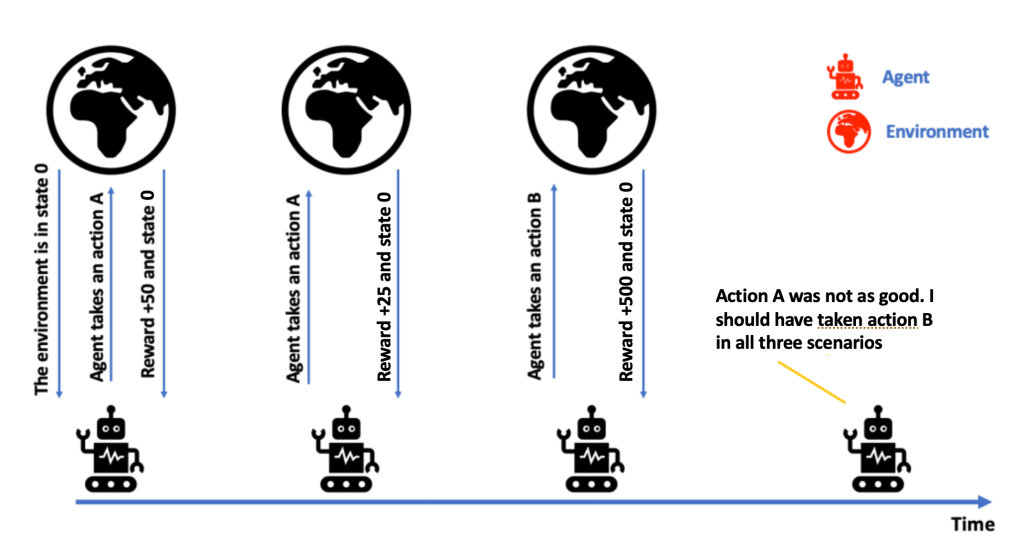
If an agent has partial knowledge about future states and rewards, it will be in dilemma on whether to exploit the partial knowledge to receive some rewards or it should explore unknown actions which could result in much more significant rewards. The agent can not choose to both explore and exploit simultaneously. This is the trade-off that needs to be managed.
The power of reinforcement learning comes from the fact that most real-world decision-making problems can be captured as reinforcement learning problems. A common way to do that is by leveraging a mathematical framework called Markov Decision Process (MDP). We will discuss this framework in the next part. The next part will be published on 07/30.
