
While in the first part of the article, we overviewed what the field of Deep Reinforcement learning is about, we started exploring some fundamental terminology in the second part and third parts. As promised in the third part, we will explore the temporal credit assignment problem in this part of the article series.
A critical capability of agents in reinforcement learning is their ability to evaluate the impact of their actions over outcomes – e.g., a win, a loss, a particular event, a payoff. Basically, their capability to evaluate how the state of the environment will change based on their action. These outcomes may also be ca result of isolated decisions taken in previous time steps since some actions may have long-term effects. The problem of learning to associate current actions with future outcomes is known as the temporal Credit Assignment Problem (CAP) in reinforcement learning.
Essentially, what we are trying to find as a solution to this problem is a way to distribute the credit for success among the multitude of decisions involved. We discussed in the previous parts that the influence that an action has on an outcome is captured in the form of associations between actions and outcomes. Learning these associations allows agents to deduce, reason, improve, and act to address decision-making problems and ultimately improve their decision efficiency.
Consider the game of soccer. The ball changes ownership every few seconds in the game, as a result of a plethora of players taking actions. These actions can be passing the ball or kicking the ball (or picking the ball, if it is the goalkeeper). The game will end with three probable results for any team, a win, a loss, or a tie. Let us assume that your team has won and in the locker room, the coach does a team huddle after celebrations. The coach and players and analyze the match and the performance of every player. They discuss the contribution of each player to the result of the match, which is a win. The problem of determining the contribution of each player to the end-result of the match ( a win) is a good example of the temporal credit assignment problem.
Let us look at this from the perspective of the agent, as shown in the illustration below.
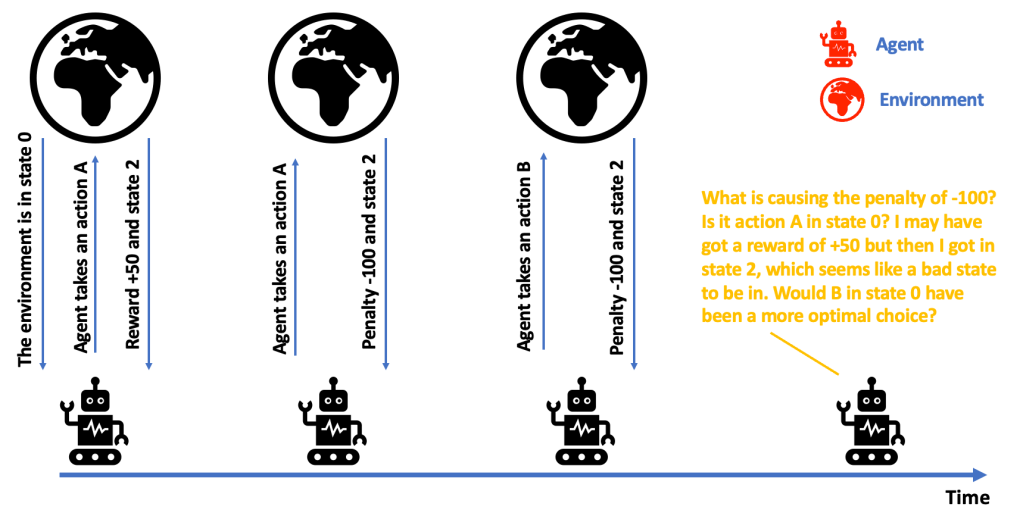
The agent has a some tough questions to face, as it is stuck in state 2, a state where it seems that its actions are leading only to penalties. The agent has many questions. What is causing the penalty of -100? Is it action A in state 0? I may have gotten a reward of +50 , but then I got into state 2, which seems like a bad state to be in. Would B in state 0 have been a more optimal choice? The questions that the confused agent has capture the problem. The problem of temporal credit assignment. As we move forward in our article series, we will explore some more details of sequential feedback in isolation.
In the next part, we will start with a discussion of the difficulty of exploration vs. exploitation trade-off. The next part will be published on July 29th.
