
While in the first part of the article, we overviewed what the field of Deep Reinforcement learning is about, we started exploring some fundamental terminology in the second part. We will continue that discussion of understanding the essential components in this part before we start exploring additional details.
The figure below shows the reinforcement learning cycle leveraging some of the terminologies that we have discussed so far. We understood the definitions of agent, environment, states, observations, transition function, reward function, and the model of the environment.
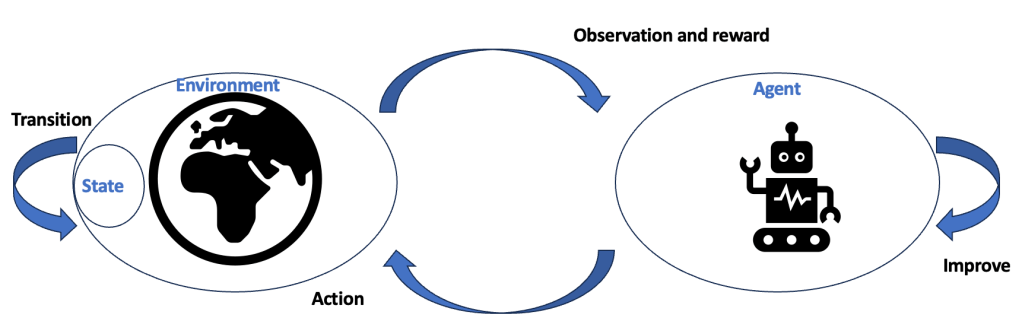
As you see in the illustration, the cycle starts when the agent observes the environment. Based on the observation, the agent leverages the reward to improve the objective it is focused on. The agent then performs an action on the environment, in an attempt to change the state in a favorable way. Finally, the environment transitions and changes its state as a result of the previous state and the agent’s action. Then the cycle repeats.
A critical aspect central to DRL is that to achieve the goal, the agent needs to demonstrate intelligence or at least cognitive abilities commonly associated with intelligence, such as long-term thinking, information gathering, and generalization. All these traits are leveraged by the agent when it executes the following steps:
- It interacts with the environment
- It evaluates the behaviour of the environment
- It improves its own responses
Over a period of time, the agent learns how to map actions and the impact of actions on the environment through observations. It can capture this relationship between actions and impact as policies. The agent can also build a model of the environment which obviously (duh!) is called the model. The agent can also learn to estimate the mappings of the reward-to-go in the form of value functions. As you can imagine, all these learnings allow the agent to understand the impact of the actions it will take on the environment and the impact on its end objective.
The interactions between the agent and the environment obviously happen over many cycles. Each cycle is referred to as a time step. During each time step, the agent analyzes the environment and takes action based on its analysis, and as a result of that action, a new observation and reward emerge. These elements of the state, the action taken by the agent, the reward, and the new state that emerges collectively are called an experience.
Remember that there may not always be a natural ending to agent’s objective. Tasks that have a natural ending are referred to as episodic tasks. On the other hand, tasks that do not have a natural ending are known as continuing tasks, like learning forward motion. The series of time steps from the beginning to the end of an episodic task is called an episode. Remember that an agent may take many time steps and episodes to learn to solve its task. They learn through trial and error, trying something, observing the result, learning from the result, then again trying something else, and henceforth.
In the next part, we will start exploring some more intricate concepts now that we have covered some of the fundamental definitions. We will start the next part by understanding the temporal credit assignment problem, a result of sequential feedback. The next part will be published on July 27th.
