
We know that at a high level, a neural network tends to learn the direct correlation between the input and target datasets. This high-level view of a neural network can be considered the clean slate approach of neural intelligence. If a neural network cannot interpret the correlation between input and output data, it’s obviously broken. If the neural network architecture gets increasingly complex, the driver generally is based on the necessity to find more complex patterns of a direct correlation.
We hear the term hidden layer in a neural network all the time. These are the layers between the input and output layers, as shown in the figure below. However, many beginners may wonder what these hidden layers actually do. We try to understand that in simple English in this article.
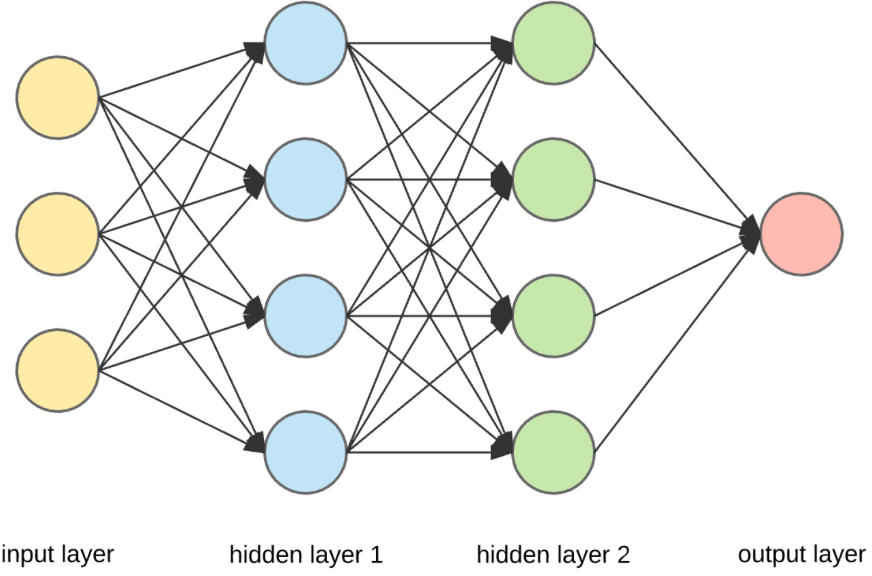
While this may seem like an extremely simplified perspective, at a high level, we can say that hidden layers are about grouping output from a previous layer into x number of groups where x is the number of neurons in that specific hidden layer.
Each hidden neuron in a hidden layer takes a data point and analyzes it with the objective of finding the answer to the following question: Does this data point belong to my group? Essentially, during the learning process, the hidden layer searches for meaningful groupings of its input.
So what exactly will be considered a useful grouping? The input data point grouping is considered useful if, above all, it is useful for the prediction of an output label. You have to remember that these meaningful groupings need to exist in data so that the network can find these groupings.
The second aspect of being useful is if the grouping captures an actual phenomenon embedded in the data that is relevant for the analysis. As an example if you are building a model to predict whether an online review of a product is positive or negative, what would constitute as a powerful grouping is the difference between “bad” and “not bad”. As you can imagine, the capability to have a neuron that turns off when it comes across “bad” and turns on when it comes across “not bad”, is what we strive for. Obviously, these groupings would be powerful inputs for the next layer.
At this point, we can generalize that the hidden layer essentially groups the data from the previous layers. From a granular perspective, every neuron in the layer classifieds a data point as either belonging or not belonging to its group. To summarize, we can generalize that two data points, in our case two product reviews, are similar if they end up subscribing to many of these same groups. Also, any two input words are similar if the weights that link them to hidden neurons (weights being the measure of each word’s group affinity) are similar.
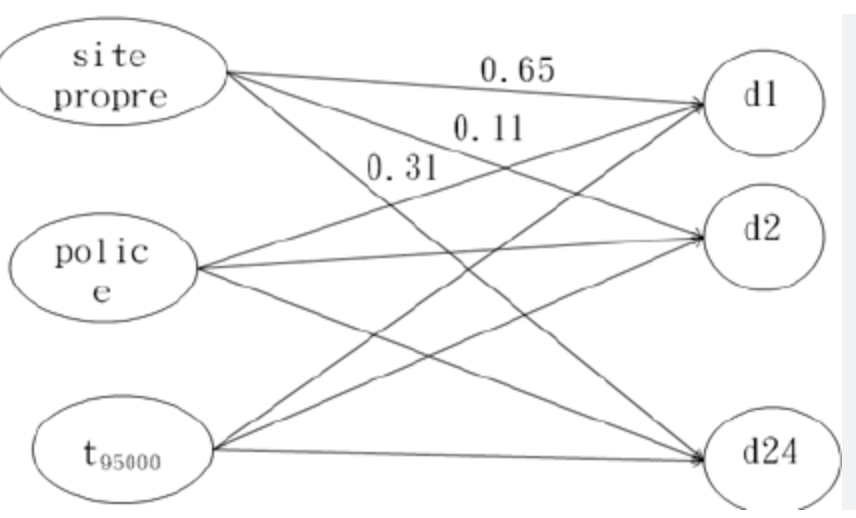
Hence, words that have similar power to predict, whatever we are trying to predict, would generally subscribe to the same group groups. By groups we mean hidden neuron configurations. Also, for words that correlate with similar labels, whether positive or negative, the weights connecting them to various hidden neurons will be similar. The reason behind this is simple. The network essentially learns to categorize them into similar hidden neurons so that the final layer of the network can make the correct prediction.
So in an extremely simplified way, this is what hidden layers help us do in neural network architecture. 😁
