
Vector similarity is leveraged widely for search applications. However, the use of vector similarity extends beyond search. Having unstructured data in vector form allows for many additional ways to interact with that data. Several additional techniques can be leveraged by vector representation in addition to the traditional kNN search. Additional methods include dissimilarity search, diversity search, recommendations, and discovery functions. In this article, we will explore the discovery function.
In order to understand how similarity models are trained, with the help of illustration below. Like most other model training approaches, there is a loss function involved. The loss function most widely used is a triplet loss function. In triplet loss function, the model is trained by fitting the information of relative similarity of there components:
- Anchor item
- A similar item (Positive)
- A dissimilar item (Negative)
Figure 1 : Triplet loss method
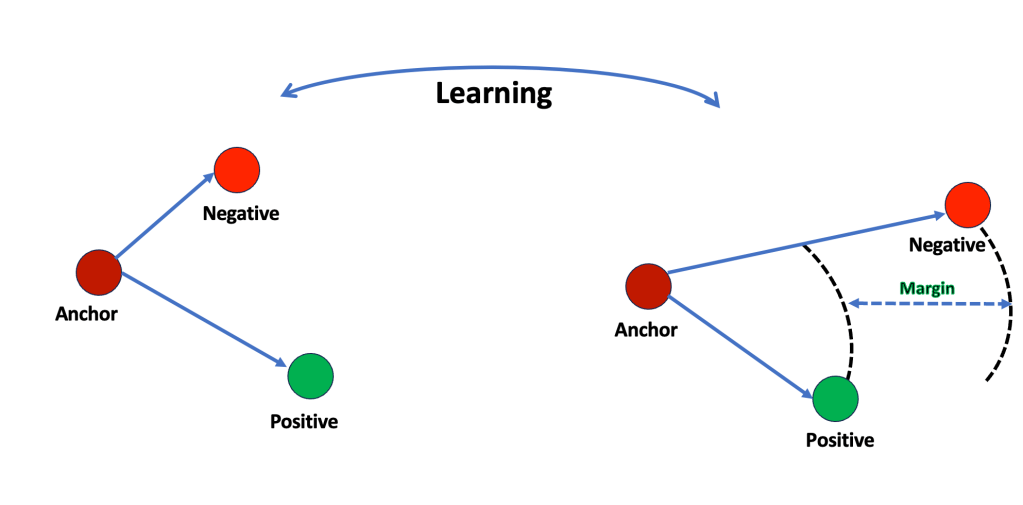
The triple loss methodology aims to make the model understand that the anchor item is closer to the positive than the negative item. This methodology helps the model distinguish between similar and dissimilar items more effectively. An example is in the area of face recognition. The model can compare two unfamiliar faces and determine if they belong to the same person. The discovery approach leverages these three parameters but from a different perspective.
In discovery, you can look at the training process differently. The approach here is that given a trained model, you can feed positive and negative examples to the model and let it find the anchor. The goal of the model then becomes finding suitable anchors across the stored collection of vectors. It is generally referred to as the reversed triple loss approach.
If you are wondering how the discovery approach differs from the recommendation, remember that the key difference is that the positive-negative pairs in discovery do not assume that the final result should be close to positive. Instead, the assumption is that it should be closer than the negative example.
Why do I believe the discovery process is robust? Beyond the images, audio, and videos? Suppose we can leverage the scalar array to vector conversion approach and transition our conventional databases into vector data (replicate, of course). In that case, we can use the discovery capability to automate some forms of analytics to levels that did not exist before.
Remember that what is challenging to do in this entire approach is not the vector similarity, triple loss approach, or anything related to RAGs and LLMs. It is to design the methodology to convert the traditional database into array structures functional to mine in vector format. It is not plain vanilla conversion of existing tables into vector formats.
The good news is that this can be done. You must leverage a data product approach to build arrays for each function/sub-function/entity. In a separate article, we will discuss, with the help of an example, how you can approach these conversions. But for now, what is important to remember is that if successfully executed, the rewards will be enormous.
