
We will follow an overview path to understand the role of vector databases in Enterprise AI. We will start with understanding vector embeddings, which will help us understand vector databases better. We will then explore how vector databases work with RAGs in an Enterprise AI context and close the overview with an example. So, let us get started.
Vector Embeddings
I assume you are familiar with Natural Language Processing (NLP) tools, that can interpret unstructured data, like words in a document. Tools that perform tasks, like capturing meanings and relationships between words in a document, convert the data in those documents (words and sentences) into a specific format, into numbers, so that they can be interpreted by the algorithms. This process is called vector embedding. So, if we were to formalize vector embeddings as a definition, it will be:
Vector embeddings help convert words and sentences, and other forms of unstructured data, into numbers that capture the meaning and relationship of those words and sentences.
Due to their popularity, we are all very familiar with Large Language Models (LLMs), like the ones powering ChatGPTs and BARDs of the world. These LLMs can transform regular data into vector embeddings and store these embeddings in the vector space. The numerical form of these vector embeddings helps identify semantic meaning in the data, relationships, or patterns and clusters.
Let us overview some popular (frequently used) types of embeddings
- Word embeddings represent each word as a vector
- Sentence embeddings represent whole sentences as vectors.
- Document embeddings represent documents, like emails, academic papers, books) as vectors.
- Image embeddings represent images as vectors by capturing a gamut of visual features.
- User embeddings represent users in a system or platform as vectors and capture details like user preferences, behaviors, and characteristics.
- Product embeddings represent products in e-commerce or recommendation systems as vectors. These embeddings capture attributes, features, and any other semantic information available on the product.
As you can interpret from the definition and description, Regular databases like RDBMS or NoSQL databases can not effectively store vector embedding data with multi-dimensions. That is why we need a vector database. Let us understand vector databases before understanding how they can play a role in Enterprise AI.
Vector Database
The challenge of working with vector data is that traditional scalar-based databases can’t keep up with the complexity and scale of such data, making it difficult to extract insights and perform real-time analysis.
Vector databases come to the rescue by offering optimized storage and querying capabilities explicitly designed for embeddings. Vector databases bring the flavor of a traditional database to vector embedding data that does not exist in standalone vector indexes. These databases also act as specialized databases for dealing with vector embeddings, which traditional scalar-based databases lack. They allow you to add advanced features to your AI applications, like semantic information retrieval, long-term memory etc.
Emerging role in Enterprise AI with RAGs
As highlighted in my article, How RAGs Are Transforming Enterprise AI, I provided an overview of how RAGs can help organizations leverage LLMs with their internal data repositories. Let us understand how vector databases fit into the context. Figure 1 illustrates an overview of the architecture:
Figure 1: Overview of vector database-enabled RAGs
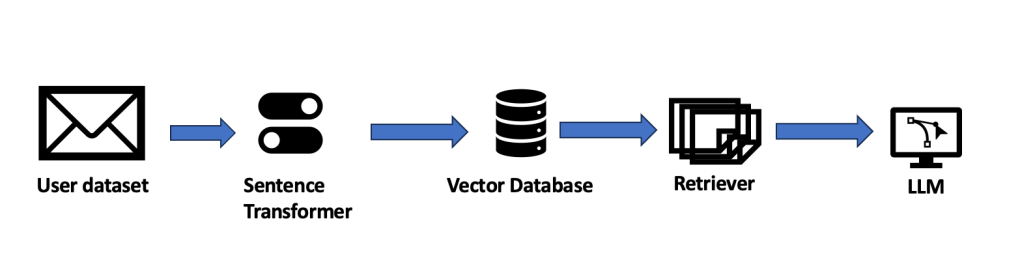
Now let us use the architecture above to illustrate an example of how this architecture helps add a whole new level of capability to Enterprise AI. The example has been illustrated in Figure 2.
Figure 2: An example interaction
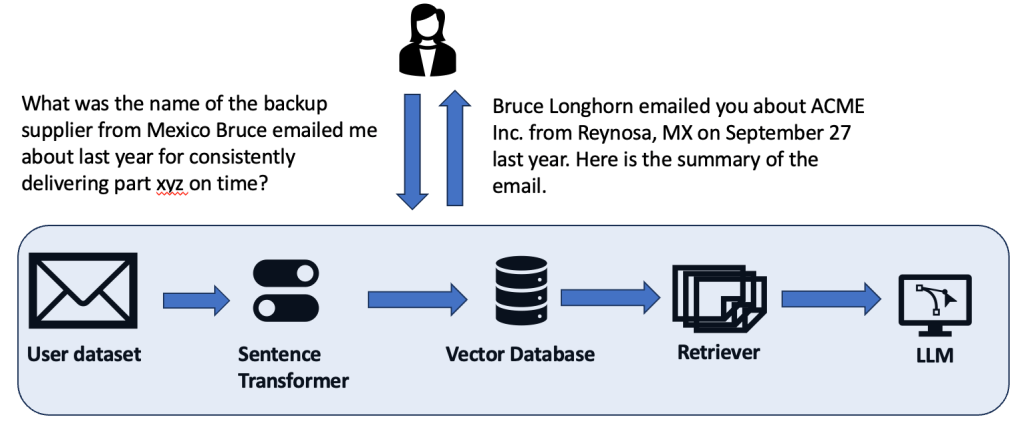
Right now, we are mostly fixated with applications in word, sentence and document embeddings, when it comes to uses like the one illustrated above. But the real opportunity, one that will completely explode the usage of LLM-powered assistants in Enterprise applications, is where you can go beyond text into numbers. We know that RDBMS databases can be converted into vector databases as well. If you are unfamiliar, this blog, How I Converted Regular RDBMS Into Vector Database To Store Embeddings, is a good introduction.
This essentially allows us to use LLM-powered assistants in more powerful ways than ever. Now, an OpenAI Dev Day announcement a couple of months ago may seem like it will kill the very need for vector databases. If you are unfamiliar with it, OpenAI released an integrated retrieval feature. But as you may have realized at this point, it is far from where you need it to be to build unique capabilities like the ones highlighted above. You can read more about OpenAI’s integrated retriever in the article, Do We Still Need Vector Databases for RAG with OpenAI’s Releasing of Its Built-In Retrieval?
Vector databases are still an excellent foundation for building unique capabilities in your enterprise application AI assistants. Exciting times!
