
While researching a specific application of Generative Adversarial Networks (GANs), I came across Siamese neural networks, which in the beginning, to me, seemed similar to GANs. A little bit of reading highlighted that though they also have two networks, they differ greatly from GANs. Curiosity pushed me to delve deeper and deeper into the capabilities of this network. As I researched the applications, many potential use cases in data and analytics emerged. One such application was in the area of data quality management.
Before we explore that, let me highlight the difference between GANs and Siamese networks. I provided a simplified overview of GANs in the article Leveraging GANs in Smart Vision Solutions. Essentially, at a high-level, the networks in GAN are competing against each other (hence the name adversarial), as shown in the Figure 1.
Figure 1 : General overview of GAN
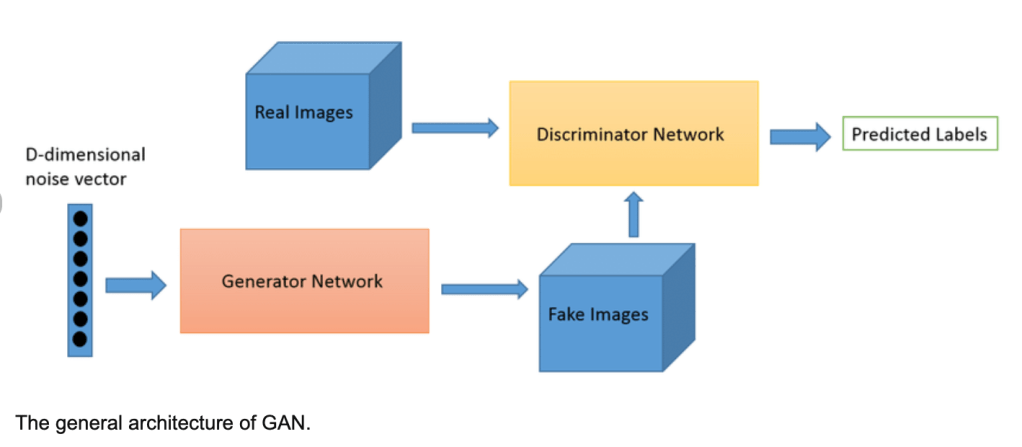
Source: ResearchGate
Siamese networks (SNNs) also have two networks that work together, but unlike GANs, these networks do not compete against each other. Siamese NNs are named so because the two networks are identical, and these two are working one beside the other rather than competing. They compare the networks’ output on two different inputs and then measure their similarity, as shown in Figure 2.
Figure 2: Overview of a Siamese Neural Network Architecture
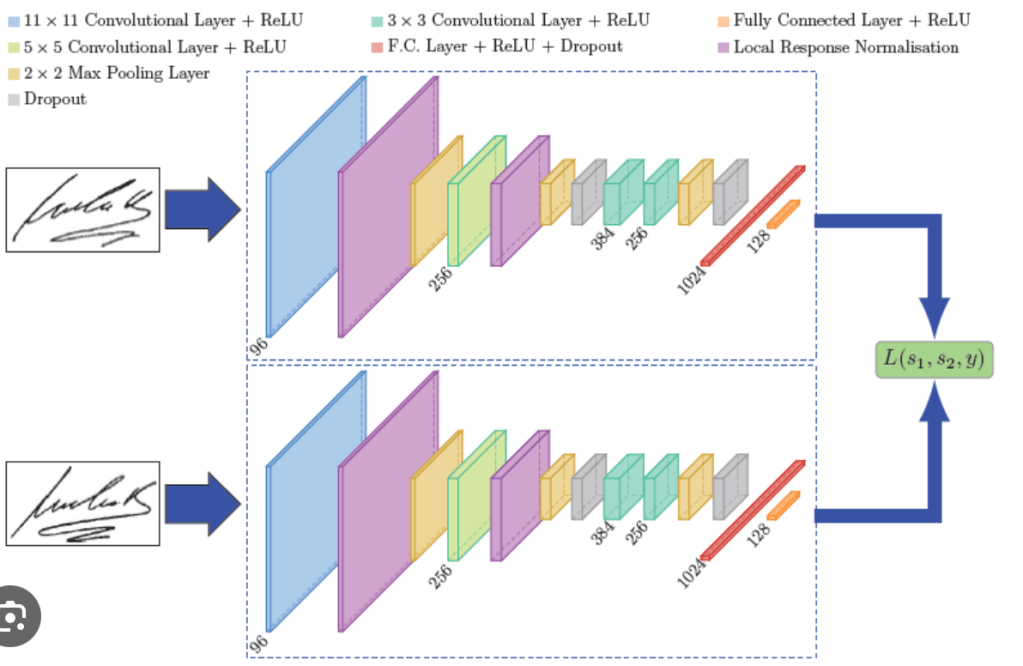
Source: Towards Data Science
The area of applications of SNNs are plenty. Some research papers pertaining to applications have been highlighted below.
A Survey on Applications of Siamese Neural Networks in Computer Vision
Survey on Siamese Network: Methodologies, Applications and Opportunities
Siamese neural networks in recommendation
Semantic Textual Similarity with Siamese Neural Networks
One application that emerges prominently is comparing text, specifically text semantics comparison. As I read through some papers on this topic, the application of this algorithm for data quality enhancement emerged prominently.
Now, let us explore a use case, leveraging the example of a challenge we frequently encounter in the arena of data quality. Data quality of master tables like material masters. Pick any specific master table that is a large volume, like a material master. The number of ways your material master data is scre*w*d is plenty despite having field-specific checks. From multiple SKU IDs for the same material to a non-standardized way of feeding material description.
One context that you may find is that users have entered multiple SKU IDs for the same material. One way to find this is by going through the material description. But since that description has been entered manually, the description is not exactly the same, but similar. This is an excellent example of how Siamese networks can find material descriptions that have similar semantics. Now, think about embedding this into an augmented analytics feature. As soon as the user enters the description and submits a new material ID, the augmented analytics bot will ask if they are entering a duplicate, with examples of similar material descriptions.
Above is just one example. By using a portfolio of deep learning algorithms, along with rule-based heuristics, organizations will be able to get a handle on most of their data quality issues in the future. This, in turn, will impact the analytics cycle time as well as insights accuracy. The future holds exciting things for data and analytics professionals!
