
Before we jump into understanding what federated learning can do for supply chain from an Industry 4.0 perspective, let us start by understanding what federated learning is. First, let me give you the technical overload definition:
Federated learning is an iterative training process that works by leveraging training iterations. During each learning iteration, edge devices train a local model using their data and transmit only the updated model to the central server, keeping the data leveraged for modeling private. The central server aggregates the parameters received into a single global model and returns its parameters to the edge devices.
Now, let us understand this in simple English. You are an e-commerce company that has a few different departments that leverage customer data for different purposes. Each of those data sets has IID data, personal data that can help identify individual customer, the data that should not be shared. However, the company is trying to build a model that needs to leverage aspects of data from these different data sources. We have a conundrum here. And federated learning can help solve that. The property of federated learning, where it can leverage the necessary parameters from other models, makes it a suitable solution for applications comprising multiple entities, and are required to learn from data, while operating under privacy requirements.
The original Google paper that proposed Federated learning was “Communication-Efficient Learning of Deep Networks from Decentralized Data”. As you can interpret from the paper, the primary focus of federated learning is around edge devices, and this is why its applications in Industry 4.0 are plenty. We are discussing supply chain-related applications in this article, but opportunities exist in marketing, specifically on-the-floor customer experience in stores.
And while we can leverage the federated architecture as envisioned, most models in supply chain operations may not be constrained by IID data. This means that we can repurpose the federated architecture to exchange model output parameters with other models directly without going through a central server, as shown in the figure below.
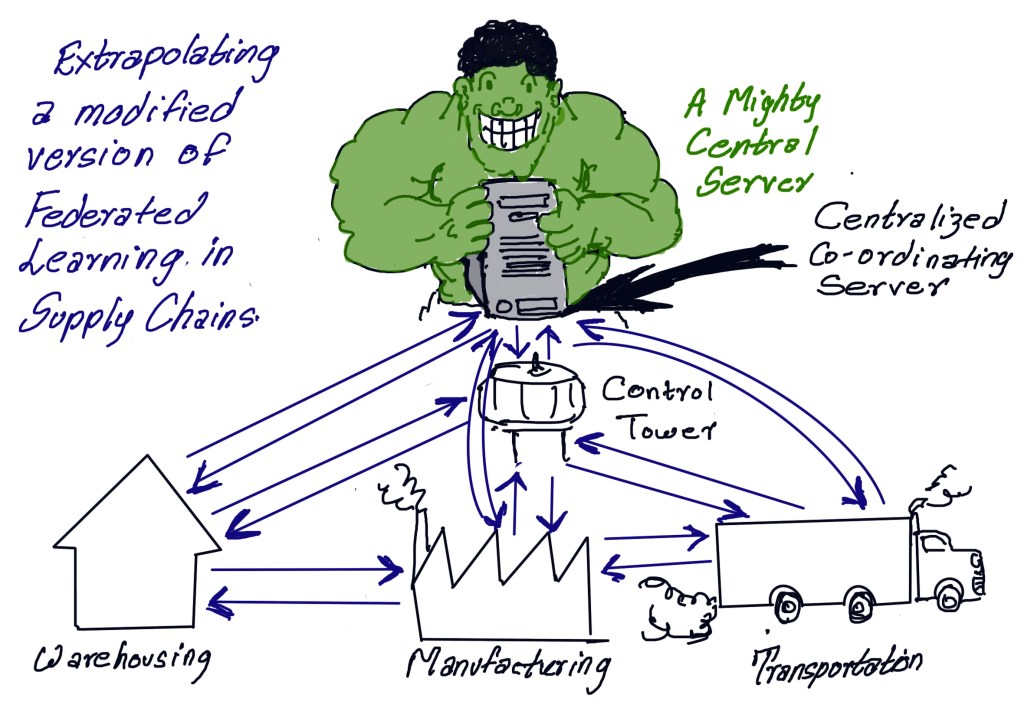
There is no doubt in my mind that complex supply chains will eventually be managed by deep learning algorithms. However, the nature of supply chain networks makes it difficult to implement the idea of a master algorithm. Architectures like federated learning can help address these challenges.
The idea behind centrality in supply chain planning stems from the fact that the end-to-end view is critical for optimality. With the federated architecture model and removing the constraint that all shared model parameters must go through the central server, we can build a network of deep learning models that may not even need a centralized deep learning algorithm.
Now let us extrapolate this to true Industry 4.0 scenarios where EdgeAI is involved. From smart manufacturing to smart warehouses, EdgeAI will soon be ubiquitous. But in instances where these edge devices are within the four walls of a manufacturing plant or warehouse, they can share the parameters with deep learning algorithms already being leveraged for various warehouse operations. However, in the case of remote applications, the federated learning model is a great fit since the model parameters can be shared directly with the central server. An example is an edge device that analyzes the ambient parameters of a reefer trailer.
