
With all the hype and buzz around data science and advanced analytics, it almost feels like a robotics, automation, and machine learning renaissance. Much of this hype is well deserved. Remember that technology has played a significant role in transforming our world, and it seems we are on the cusp of what we call “The Digital Transformation” age.
This article focuses on leveraging machine learning in Inventory planning-The Why, the How, and the When.
Before you read further, please remember that these are my views and perspectives. The data science domain is rapidly innovating and still in flux. Different practitioners have different perspectives, and this is what makes interactions great as we get to learn from each other.
The data science frenzy and its adaptation to operations and supply chain
The Digital age has impacted all critical business functions, like marketing, finance, and operations. Operations-specifically supply chain, from my perspective, has been a unique function as far as the adoption of “digital” goes.
Before the word “Big Data,” giant warehouses embraced automation systems, and automated production lines worked with the precision that could be compared with that of Swiss-made watches.
However, the same can’t be said about adapting machine learning methodologies in supply chains.
Though Industry 4.0 has created its buzz, and we are actively discussing how Big Data technologies can “transform” supply chains, the actual adaptation has been relatively slow. Some best-in-class companies are taking the lead and working hard and strong to get that competitive edge by being the first ones to harness the power of data science and, more specifically, Machine Learning (ML) control.
Since this article focuses on Inventory, I will keep that focus from now onward. We will talk about the application of ML in Inventory analytics, but before that, we need to get a quick perspective on where we currently stand in that arena.
A very, very brief history of advanced analytics in inventory management
Unfortunately, the inventory analytics journey that started in the early 1990s with the classic deterministic EOQ model has not come far enough from there as far as the Inventory analytics methodologies go. As we know, the primary trade-offs in the traditional EOQ model are holding cost vs. fixed costs and economies of scale. Inventory management in the real world is much more than just their parameters. Then the Newsvendor model was adopted, primarily to address the variability aspect, and from that evolved the classic Inventory models that take variability into account.
The current widely used inventory models, like Base stock, Order upto, and additional variations, are focused primarily on safety stock and build upon the variability aspect addressed by the Newsvendor model. However, in my perspective, this is where the journey slowed down. We got too fixated on safety stock calculations. While managing safety stocks is crucial, the standard models used are very standardized, with only a handful of parameters being used/considered to calculate Inventory requirements and manage Inventory.
The only primary modifications to classic inventory optimization/analytics processes that I have observed recently are:
- Better demand categorization/classification: Focus on leveraging data science has led to more sophistication in Inventory models by defining the demand distribution better. Rather than force-fitting every demand pattern into a normal distribution, we can be more precise in determining the distribution type. However, the calculation parameters are still the same.
- Forecasting is evolving: Since we typically use forecasted demand and forecasting algorithms are growing fast-the, models are getting better than before, but the pace is not significant enough (my perspective).
So what is not exactly right with the current methods?
My belief is it is our fixation with calculating safety stocks.
This fixation then gyrates us into using the same models repeatedly without putting too much thought into what goes into these calculations and how these calculations can be improved/refined.
I have always been passionate about applying advanced analytics in supply chain and operations domain. But the analytics I love using is the one that would deliver results and would consider real-world challenges.
The crux of the problem with the current Inventory management modeling approach (in my belief) is that real-world challenges extend beyond simple parameters and assumptions that form the underlying basis of the classic Inventory models.
Why this has not been challenged enough?
I don’t have the complete answer to it, but I believe that at the heart of it is the plethora of off the shelf “Multi-Echelon Inventory Optimization (MEIO)” tools that are out there in the market. The companies selling these solutions leverage marketing to differentiate but the fact is the underneath most of these tools are very similar.
No matter how many fancy functionalities are incorporated into these tools, the underlying calculations are still simple and, in my opinion, dated,in today’s era.
There have been advances, though-but they have been mainly on the user interface, ease of use and technology front-not on the design and algorithm side. These advances are important as well and help increased penetration of analytics. But the opportunity to build solutions that go beyond the traditional calculations is huge.
With technological advances, even a powerful laptop can host a MEIO tool, which can perform millions of calculations. This should excite us but not to the extent of believing that we have made advances in the approach of Inventory modeling. All we have done is enhance the capability of calculating millions of values using an archaic model.
Millions of calculations are great-but. How valid are those values? How widely are these numbers trusted and embraced by the planners? Will these values make an actual sustainable impact on your Inventory? Will it help you become a best-in-class organization as Inventory planning and management go?
We seem to forget the key aspect-the win is not in successfully implementing a solution. Success is getting the maximum value out of that solution. And keep that value forever.
Win is leveraging that solution to solve your business/operational problems. The world is full of stories of “successful” ERP implementations (back when ERP was the buzz) that delivered little to no value and, in some (unique) instances, led companies to file for bankruptcy.
So how can Machine learning help?
To understand this, we will leverage a two part approach:
- Go through an example of how machine learning algorithms can help do more effective inventory planning and why it is better than the classical approach.
- Understand what are the critical challenges in implementing such solutions-going beyond the “perfect world” theories?
Inventory Strategy formulation (an ideal approach)
Before we delve deeper into machine learning applications in Inventory management, we must understand what factors influence Inventory policies. As you can see in the illustration below, Inventory policies can’t be created in silos since so many strategies impact your Inventory strategy.
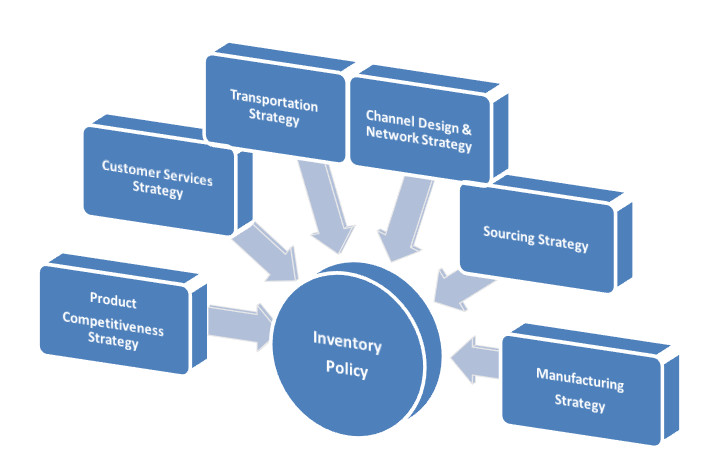
I firmly believe that current Inventory models that use only a handful of standard parameters are not equipped to help you plan a strategy that many other techniques can influence.
Leveraging Machine learning for Inventory planning will allow you to truly exploit the Big Data revolution
Organizations today hold a massive amount of data, but only a minuscule portion of that data set is used in Inventory models. A primary driver behind this is the capability of Inventory modeling systems. First, they are pre-built with limited input parameters. Second, even though the calculations are “automatic,” I don’t know of many organizations that will allow these numbers to flow directly into their buying systems. Sourcing professionals/planners in most organizations that use such tools understand that these numbers can’t be trusted.
A Machine learning algorithm that has been custom designed is limited only by the computing power of the machine that runs it. It can tap into and analyze hundreds of data points, and the end users (say planners) can also “train” the algorithm using their tribal knowledge. The same algorithm can be “trained” differently by each planner based on the product portfolio they plan for.
How machine learning can help us create the next generation of Inventory planning systems
Let us imagine that we have developed the tool that I envision. We will call our Machine learning algorithm “REALISTIC.” REALISTIC, unlike other Off-the-shelf tools, is not a cookie-cutter tool. Its algorithm has been tailored to suit your business needs and model. REALISTIC is fed Terra bytes of historical and current data about (not an exhaustive list):
- SKUs- Description, weight, volume, primary packaging, secondary packaging.
- Sales data: Historical sales data at the SKU level by geography, weekly or daily status.
- Manufacturing data: Production capacities historical data, current and projected capacities, at the production line level.
- Transportation data: Actual historical data with detailed info on what SKUs typically go by which mode, by carrier, for each lane. Carrier performance metrics history is also a critical part of this sub-set of data. Historical and projected taxes, duties, and surcharges will also be included here.
- Economy and Market data: Market historical and projected data (growth/decline etc.), Economy trends and related for the last two years, and upcoming projections. Related trends, like carrier capacity crunch, etc.
A little bit about reinforcement learning
In my example, I will use one specific machine learning methodology called Reinforcement learning. The focus of this article is to illustrate how Machine learning can help refine the Inventory planning process, so I will not get into the technical details of Reinforcement learning but below is a very brief explanation:
Reinforcement learning is a Machine learning algorithm that aims to maximize some long-term reward. Having been trained with initial data, these algorithms begin by trying various actions, observing the resulting rewards from these actions, and then learning to improve their efforts accordingly. The critical point here is that these algorithms are not programmed to execute any pre-determined strategy-they know on their own.
Pre-defined Inventory policies do not constrain the reinforcement learning based Inventory planning algorithm
Because the world is not Black or White, remember that some additional aspects were incorporated in Inventory models to account for variability-for example, lead time variability. However, we then apply standard approaches to calculate the variability (Standard Deviation, assuming a Normal distribution, etc.), making the idea mute.
The excitement around Big Data is primarily because, given the right capabilities, every data point can be a contributor. A reinforcement learning-based Inventory planning algorithm will be able to do precisely that. So we end up with the following:
- There is no need to create rigid product groups; each product’s unique characteristics can be analyzed and incorporated by the algorithm. However, suppose computational power and other resources are a constraint. In that case, the algorithm can group products as well, based on various characteristics that go beyond the brute force approach of creating product groups.
- No need to assign a pre-defined Inventory policy (like (s, S),(S,q), etc.). The model will decide based on millions (or maybe trillions) of values it analyzes. It will maintain inventory levels at the SKU level or Product groups based on numerous input parameters. For each parameter, we feed it a gigantic amount of data, both historical and projections.
The reality of developing and implementing realistic solutions
Now comes the problematic part-how realistic is it to create and implement something like this?
The critical point is that this will be a customized solution. Whether you need to invest in a capability like this or not depends on a few aspects like (not an exhaustive list):
- Your product portfolio: There are several standardized approaches to Determining what type of products your portfolio has. If your SKUs have very predictable demand, you make to stock, and the variability and unpredictability in your business model are minimum, you probably can keep leveraging the Off-the-shelf tools
- Size of your business: Investing resources into developing and implementing something of this scale can be daunting. Initial investments can be huge. And since these algorithms will take time to learn, there needs to be realistic expectations on the initial ROI. These factors make such solutions more compatible with large organizations willing and capable of investing time and money.
- Infrastructure: Let us be honest about this-your IT Infrastructure matters a lot as far as implementing any Machine learning algorithms goes. It is not just about computing power but a plethora of other IT-related capabilities like Data quality, the interconnectivity of systems, actual data flows, etc. Having a solid technology is one of the foundational aspects of implementing Machine learning tools, so if you believe you are not there yet, take care of this aspect before moving on to the next milestone.
- Processes: Systems are built around processes (specifically, customized systems). You don’t want to make an infrastructure around processes that are broken. If your procurement or Inventory management methods are subpar, your focus should be business process re-engineering before you start modernizing/rebuilding systems around the processes.
- Talent pool: One of the most critical aspects is having the correct type of talent that can support these future tools. The right kind of talent does not mean more data scientists. It means that the end users are techno-savvy enough to understand what the tool is doing, how they can influence the algorithm to make it “learn,” etc.
The Road ahead
My perspective is that it is high time we think beyond the archaic Inventory management systems that have bogged down the advanced in Inventory planning analytics so far. The technology and talent to support such an initiative is in place now-is your organization game enough?
